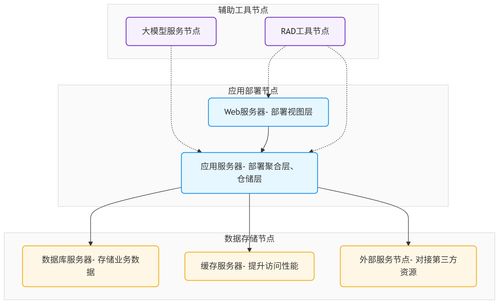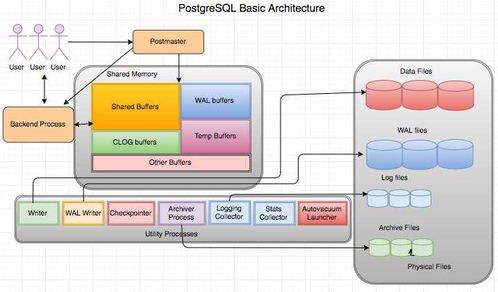
随着云计算、大数据和微服务架构的普及,后端数据库的选择和数据存储处理服务呈现出多元化、专业化的发展趋势。当前,后端开发者通常会根据应用场景、数据结构、一致性要求、扩展性及成本等因素,选择合适的数据库和数据处理存储服务。
一、主流数据库类型与应用场景
- 关系型数据库(SQL)
- 代表产品:MySQL、PostgreSQL、Microsoft SQL Server、Oracle Database。
- 特点:支持ACID事务,数据以表格形式存储,适合结构化数据和复杂查询。
- 应用场景:金融交易系统、企业资源规划(ERP)、内容管理系统等需要强一致性和事务支持的场景。
- 非关系型数据库(NoSQL)
- 文档数据库:如MongoDB、Couchbase,适用于存储半结构化数据(如JSON),灵活性强,常用于内容管理、用户配置等。
- 键值数据库:如Redis、Amazon DynamoDB,读写性能高,常用于缓存、会话存储和实时应用。
- 列存储数据库:如Apache Cassandra、HBase,适合大规模数据写入和读取,常用于日志分析、物联网数据存储。
- 图数据库:如Neo4j、Amazon Neptune,擅长处理复杂关系数据,应用于社交网络、推荐系统、欺诈检测。
- 新兴数据库技术
- 时序数据库:如InfluxDB、TimescaleDB,专为时间序列数据优化,用于监控系统、物联网数据收集。
- 向量数据库:如Pinecone、Milvus,支持向量相似度搜索,是AI和机器学习应用的核心组件,用于推荐、图像检索等。
二、数据处理和存储支持服务
现代后端架构不仅依赖于数据库本身,还广泛使用云服务商和开源工具提供的支持服务,以提高数据处理效率和可靠性:
- 云数据库服务
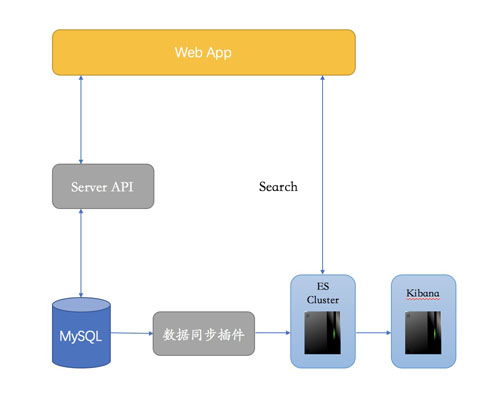
- 各大云平台(如AWS、Azure、Google Cloud)提供托管的数据库服务(如Amazon RDS、Azure SQL Database、Google Cloud SQL),降低了运维负担,并支持自动备份、扩展和监控。
- 数据缓存与加速
- 缓存服务:如Redis、Memcached常用于减少数据库负载,提升响应速度。云服务商也提供托管缓存服务(如Amazon ElastiCache)。
- CDN(内容分发网络):如Cloudflare、Akamai,用于静态数据和媒体文件的全球加速。
- 大数据处理平台
- 数据仓库:如Snowflake、Amazon Redshift、Google BigQuery,支持海量数据分析与商业智能(BI)应用。
- 流处理:如Apache Kafka、Amazon Kinesis,用于实时数据摄入和处理,适用于事件驱动架构和实时分析。
- 批处理:如Apache Hadoop、Spark,用于离线数据分析和ETL(提取、转换、加载)流程。
- 数据湖与对象存储
- 对象存储服务:如Amazon S3、Google Cloud Storage、Azure Blob Storage,成本低廉,适合存储非结构化数据(如图片、视频、日志文件),常作为数据湖的基础。
- 数据湖解决方案:如Delta Lake、Apache Iceberg,在对象存储之上提供数据管理和分析能力,支持ACID事务和版本控制。
- 数据库即服务(DBaaS)与Serverless数据库
- 如Amazon Aurora Serverless、Google Cloud Firestore,提供自动扩缩容和按使用量计费,简化了数据库管理,适合流量波动大的应用。
三、选型考量与趋势
- 多模型数据库:如Azure Cosmos DB、FaunaDB,支持多种数据模型(文档、键值、图等),提供全球分布式能力,满足多样化需求。
- 混合事务/分析处理(HTAP):如TiDB、CockroachDB,允许在同一数据库中同时进行事务处理和分析查询,减少数据同步开销。
- 开源与云原生:开源数据库(如PostgreSQL、MongoDB)生态繁荣,而云原生数据库(如Google Spanner)强调全球一致性和水平扩展,正成为大型应用的选择。
- 安全与合规:数据加密、访问控制和GDPR等合规要求,促使开发者优先选择内置安全特性的数据库和服务。
现代后端数据库和存储服务已形成丰富的生态系统。开发者需结合具体业务需求,灵活选用SQL或NoSQL数据库,并辅以缓存、数据湖等支持服务,构建高效、可扩展的数据处理架构。随着AI和实时应用的增长,向量数据库和流处理技术也将越来越重要。